Skip to content 
LAMDA RL LAB is a subgroup of LAMDA that focuses on advancing the field of reinforcement learning (RL) and its application to creating general decision-making intelligence. Key areas we are exploring include: model-based RL and world model learning, multi-agent and collaborative RL, planning and learning with large models, etc. Through both fundamental and application research, our aim is to create RL-based systems that exhibit general decision-making capabilities.
Recent News
(in Chinese)ICLR 2026 | ADM-v2:在离线有模型强化学习中实现可靠的全视野 Roll-out
本文将介绍我们近期被 ICLR 2026 接收的论文: ADM-V2: PURSUING FULL-HORIZON ROLL-OUT IN DYNAMICS MODELS FOR OFFLINE POLICY LEARNING AND EVALUATION...ICLR'26 | EMFuse:基于能量的模型融合
本文分享我们最近发表在 ICLR 2026 上的工作: EMFUSE: ENERGY-BASED MODEL FUSION FOR DECISION MAKING 受到 专家乘积(Product-of-Experts, PoE)[1,2] 与 能量模型(Energy-Based Models...NeurIPS'25 | MAFIS: 面向可扩展多智能体模仿学习的统一框架
本文分享我们发表在NeurIPS 2025上的工作: Multi-Agent Imitation by Learning and Sampling from Factorized Soft Q-Function 在这个工作中,受到IQ-Learn[1]和能量模型的启发...NeurIPS 2025 | FTR: 在复杂环境中进行高效策略部署的强化学习方法
非常高兴我们的工作《Focus-Then-Reuse: Fast Adaptation in Visual Perturbation Environments》被 NeurIPS 2025 接收。这项工作致力于解决视觉强化学习策略在从干净环境迁移到充满视觉干扰的环境时性能下降的挑战...NeurIPS 2025 | CoPDT: 面对多任务约束以及多约束阈值的离线安全强化学习
非常高兴我们的工作《Adaptable Safe Policy Learning from Multi-task Data with Constraint Prioritized Decision Transformer》被NeurIPS 2025 接受...ICML 2025 | Lapse: 面对状态可演变环境的强化学习策略复用方法
非常高兴我们的工作《Learning to Reuse Policies in State Evolvable Environments》 被 ICML 2025 接收,这项工作致力于解决强化学习智能体在真实世界部署时,环境状态空间变化而导致策略失效的挑战...ICML 2025 | APEC:利用对抗模仿学习过程自动生成偏好数据,提升奖励模型泛化能力
非常高兴我们的工作《Improving Reward Model Generalization from Adversarial Process Enhanced Preferences》已被 ICML 2025 接收!这是我们在奖励建模(Reward Modeling...ICML 2025 | CoLA: 基于latent action控制的语言模型
在前段时间,在俞老师的指导下,我们进一步的考虑了语言模型可持续演化的结构,基于之前在模型结构上的探索 BWArea Model: 决策视角下的可控语言生成 ,设计了一种可以更加高效的做强化学习的语言模型结构:CoLA。这一工作也被今年的ICML25接收...ICML 2025 | 大语言模型辅助的语义层面多样队友生成
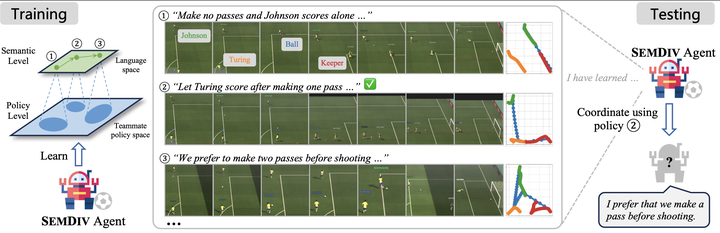 最近, 我们提出了大语言模型辅助的语义层面多样队友生成方法 LLM-Assisted Semantically Diverse Teammate Generation for Efficient Multi-agent Coordination (SemDiv)...
最近, 我们提出了大语言模型辅助的语义层面多样队友生成方法 LLM-Assisted Semantically Diverse Teammate Generation for Efficient Multi-agent Coordination (SemDiv)...NeoRL-2:面向现实场景的离线强化学习基准测试
项目页面: https://github.com/polixir/NeoRL2 文章链接:NeoRL-2: Near Real-World Benchmarks for Offline Reinforcement Learning with Extended Realistic Scenarios 研究背景与意义强化学习...